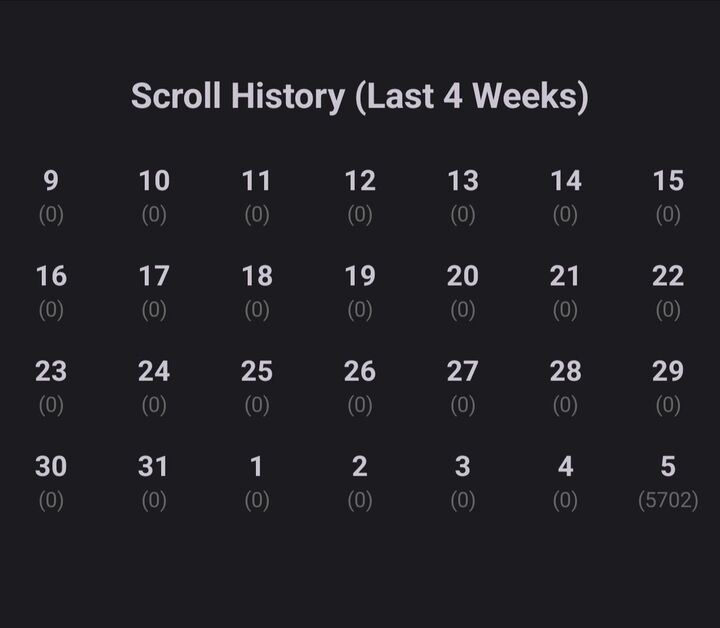
Work has started on DoooM a simple yet hopefully informative android usage tracker that reflects the recent history of scrolling activity.
Having previously made a progressive web app in the form of when-ze-bus, we're now looking at system level programming with Kotlin, a Java compatible language that can receive android's AccessibilityService events, giving it the ability to reflect on scrolling behaviours.
Scroll increments _seem_ to be measured by distance rather than individual actions: a side swish maybe just one or two points, a little vertical swish (such as when reading) will result in the counter going up a handful, but a big infinite-feed type swash can result in tens or even hundreds being added to the daily tally. I'm still getting a feel for how it works, but it does seem to be generally reflective of usage behaviours. A normal day's scrolling through feeds may see thousands, perhaps tens-of-thousands, of points being added up.
The f-doid packaging process awaits, and a couple of features lined up, but in the meantime, it can be evaluated with this package, and checksummed to confirm the file is the one intended:
Symmetry is nice, and six-fold symmetry is even nicer, so let it snow…
As well as making the above little app, this little journey took us into the fediverse over on fedibot.club from where a lua tootbot emerged. Not having a user interface makes for much nicer reading, and lua is a nice language (see below). Mostly vibes by vibe-cli, it's a bit long-winded and weird, but it was fun making a project in two languages at once.
Following much hectoring, the approach that vibe-cli and I eventually settled on was:
draw one side of a branch with varied number of sub-branches (complexity);
repeat it five more times, each rotated at 60 degree intervals;
then mirror each one by inverting the y coordinates.
-- Lua Snowflake Generator
-- Creates a six-fold symmetrical snowflake using the fedibot.club image API
-- https://fedibot.club/bots/vakoudqgeqqqltdj
-- Set random seed based on current time
math.randomseed(os.time())
local size = 512
local complexity = 5
local centerX = size / 2
local centerY = size / 2
local radius = math.min(centerX, centerY) * 0.85
local function generateOneSideBranches(radius, complexity, random)
local branches = {}
-- Add main sub-branches based on complexity
local numMainBranches = 2 + math.floor(complexity * 0.8)
for i = 1, numMainBranches do
-- Position along main branch (0 to 1)
local position = (i + 1) / (numMainBranches + 1)
-- Branch parameters
local angle = math.random() * (math.pi / 3) -- 0 to 60 degrees
local length = radius * (0.2 + math.random() * 0.3)
-- Calculate end point
local endX = position * radius + length * math.cos(angle)
local endY = 0 + length * math.sin(angle)
table.insert(branches, {
start = { x = math.floor(position * radius + 0.5), y = math.floor(0 + 0.5) },
finish = { x = math.floor(endX + 0.5), y = math.floor(endY + 0.5) },
width = 2 + complexity * 0.3
})
-- Add sub-sub-branches (0-6 per main branch)
local numSubBranches = math.floor(math.random() * 7) -- 0 to 6
for j = 1, numSubBranches do
local subPosition = (j + 1) / (numSubBranches + 1)
local subAngle = math.random() * (math.pi / 4) -- 0 to 45 degrees
local subLength = length * (0.2 + math.random() * 0.4)
-- Calculate sub-branch end point
local subEndX = position * radius +
(endX - position * radius) * subPosition +
subLength * math.cos(angle + subAngle)
local subEndY = 0 +
(endY - 0) * subPosition +
subLength * math.sin(angle + subAngle)
table.insert(branches, {
start = {
x = math.floor(position * radius + (endX - position * radius) * subPosition + 0.5),
y = math.floor(0 + (endY - 0) * subPosition + 0.5)
},
finish = { x = math.floor(subEndX + 0.5), y = math.floor(subEndY + 0.5) },
width = 1 + complexity * 0.2
})
end
end
-- Add 5 more main branches at 60 degree intervals
for i = 1, 5 do
local angle = i * (math.pi / 3)
local endX = radius * math.cos(angle)
local endY = radius * math.sin(angle)
table.insert(branches, {
start = { x = 0, y = 0 },
finish = { x = endX, y = endY },
width = 3 + complexity * 0.4
})
end
return branches
end
-- Generate complete symmetrical branch pattern
local function generateBranchPattern(radius, complexity)
local branches = {}
-- Main branch
table.insert(branches, {
start = { x = math.floor(centerX + 0.5), y = math.floor(centerY + 0.5) },
finish = { x = math.floor(centerX + radius + 0.5), y = math.floor(centerY + 0.5) },
width = 3 + complexity * 0.4
})
-- Generate right side branches
local rightBranches = generateOneSideBranches(radius, complexity)
-- Add right branches (they should already be relative to center)
for _, branch in ipairs(rightBranches) do
table.insert(branches, branch)
end
-- Create left branches by mirroring right branches over the main branch (X axis)
for _, branch in ipairs(rightBranches) do
-- Mirror: keep X coordinate, negate Y coordinate (branches are already relative to center)
table.insert(branches, {
start = { x = branch.start.x, y = -branch.start.y },
finish = { x = branch.finish.x, y = -branch.finish.y },
width = branch.width
})
end
return branches
end
-- Generate the snowflake as a Fedibot API image
local function generateSnowflakeImage()
local branches = generateBranchPattern(radius, complexity)
-- Create the image data structure for Fedibot API
local imageData = {
w = size,
h = size,
steps = {},
description = "a generative snowflake inspired pattern using six-fold symmetry" -- alt text
}
-- Add all branches 6 times with 60 degree rotation for six-fold symmetry
for i = 0, 5 do
local rotation = 90 + i * 60 -- 60 degrees per rotation
-- Draw all branches for this rotation
for _, branch in ipairs(branches) do
-- Apply rotation to branch coordinates
local startX = branch.start.x
local startY = branch.start.y
local endX = branch.finish.x
local endY = branch.finish.y
-- Rotate points around origin
local rad = math.rad(rotation)
local cos = math.cos(rad)
local sin = math.sin(rad)
local rotatedStartX = startX * cos - startY * sin
local rotatedStartY = startX * sin + startY * cos
local rotatedEndX = endX * cos - endY * sin
local rotatedEndY = endX * sin + endY * cos
-- Translate to center
rotatedStartX = math.floor(rotatedStartX + centerX + 0.5)
rotatedStartY = math.floor(rotatedStartY + centerY + 0.5)
rotatedEndX = math.floor(rotatedEndX + centerX + 0.5)
rotatedEndY = math.floor(rotatedEndY + centerY + 0.5)
table.insert(imageData.steps, {
"line",
rotatedStartX,
rotatedStartY,
rotatedEndX,
rotatedEndY,
{173, 216, 230}
})
end
end
return imageData
end
return {
status = "season's greetings. here's a snowflake inspired procedural pattern; with thanks to fedibot.club",
images = {generateSnowflakeImage()},
key = os.time()
}
After a run of a couple of days of hourly running, the bot was switched to daily just before the solstice [15:03 GMT]. Using a bot to toot one's own feed might be a bit out-of-keeping, but it gave a sense of being a semi-automated person: half man; half robot.
spanish tortilla on crispbread with wallies (pickled gherkins) and burger sauce, inspired by an episode of easy spanish.
if the wallies are sweet you could skip the sauce, as this recipe would still meet max's six rules of sandwich: hot, cold, sweet, sour, crunchy, soft.
🍠slice enough small potatoes into discs about 5mm thick to cover the base of a frying pan (sweet potatoes are also nice)
🧅chop an onion into tiny pieces
🔥heat a thin layer of oil in a frying pan on a low heat (this is very much a simmering dish). cover the base of the pan with potatoes and onions, shuffling a little to ensure no sticking
🥚while the potato and onion sizzles a little, whisk three or four eggs with salt and pepper, and pour over the potato/onion mix, use a spatula to separate the edge from the pan as it forms
🔘cover the pan with a plate and allow to simmer for a couple of minutes
🥊with a oven glove on, clasp the plate onto the pan and turn the whole thing over, then slide the tortilla back into the pan to cook the other side; cover with the plate again
🥒slice some wallies
🔥after a couple more minutes the tortilla is likely ready to serve, have a peek, you'll be able to tell when the potato has gone a bit translucent and the egg has gone fluffy (you can also flip it once more to see which side looks best on top)
🧆spread crispbread with burger sauce, slice the tortilla in the pan with a pizza cutter and lay it over the crispbread and top with sliced wallies.
2025-11-14
Abridged excerpt from a Q&A with Cory Doctorow,
in which he investigates potential uses for
language/vision models if hyperscaling is over,
hyperlocal optimised models are widespread,
and GPUs are cheap:
Let me advance a theory of the less bad and more bad bubble.
Some bubbles have productive residues and some don't.
Enron left nothing behind…
Now Worldcom, which was a grotesque fraud,
some of you will remember?
They raised billions of dollars
claiming that they had orders for fibre.
They dug up the streets all over the world.
They put fibre in the ground.
They didn't have the orders for the fibre.
They stole billions of dollars from everyday investors.
The CEO died in prison.
But there was still all that fibre in the ground.
So I've got two gigabit symmetrical fibre at home
in Burbank because AT&T bought some old dark fibre
from Worldcom because fibre lasts forever?
It's just glass.
Once it's there, it is a productive residue.
So what kind of bubbles are we living through?
Well, crypto is not gonna leave behind anything.
Crypto is gonna leave behind shitty Austrian economics
and worse JPEGs.
AI is actually gonna leave behind some stuff.
So if you wanna think about like a post AI bubble world
and I just got edits from my editor.
I wrote a book over the summer
called The Reverse Centaur's Guide to Life After AI.
And if you wanna think about a post AI world,
imagine what you would do if GPUs were 10 cents
on the dollar.
If there were a lot of skilled applied statisticians
looking for work.
And if you had a bunch of open source models
that had barely been optimised
and had a lot of room at the bottom?
I'll give you an example.
I was writing an essay
and I couldn't remember where I'd heard a quote
I'd heard in a podcast.
I couldn't remember which quote it was.
So I downloaded Whisper,
which is an open source model
to my laptop, which doesn't have a GPU,
little commodity laptop,
threw 30 hours of podcasts
that I'd recently listened to at it,
I got a full transcription in an hour
my fan didn't even turn on.
Yeah, so I know tonnes of people who use this
and the title of the book, Reverse Centaur,
refers to this idea from automation theory,
where a centaur is someone who gets to use machines
to assist them, a human head on a machine body?
And so, you know, you riding a bicycle,
you using a compiler.
A reverse centaur is
a machine head on a human body.
It's someone who's been conscripted
to be a peripheral for a machine?
I've got a very treatable form of cancer,
but I'm paying a lot of attention
to stories about cancer and, you know,
open source models or AI models
that can sometimes see solid mass tumors
that radiologists miss.
And if what we said was,
we at the Kaiser Oncology Department
are going to invest in a service
that is going to sometimes ask our radiologist
to take a second look to see if they miss something,
such that instead of doing 100 x-rays a day,
they're gonna do 98?
Then I would say, as someone with cancer,
that sounds interesting to me.
I don't think anyone is pitching any oncology ward
in the world on that.
I think the pitch is fire 90% of your oncologists,
fire 90% of your radiologists,
have the remainder babysit AI,
have them be the accountability sinks
and moral crumple zones for a machine
that is processing this stuff at a speed
that no human could possibly account for,
have them put their name at the bottom of it,
and have them absorb the blame
for your cost-cutting measures.
When I hear people talk about AI,
I hear programmers talk about AI
doing things that are useful,
So there's a non-profit
called the Human Rights Data Analysis Group:
It's run by some really brilliant
mathematicians, statisticians.
They started off doing statistical extrapolations
of war crimes for human rights tribunals,
mostly in The Hague,
and talking about the aspects of war crimes
that were not visible,
but could be statistically inferred from adjacent data.
They did a project with Innocence Project New Orleans,
where they used LLMs to identify
the linguistic correlates of arrest reports
that produced exonerations,
and they used that to analyse
a lot more arrest reports than they could otherwise,
and they put that at the top of a funnel,
where lawyers and paralegals
were able to accelerate their exoneration work.
That's a new thing on this earth:
It's very cool,
and I'm like, okay,
well if these guys can accelerate that work
with cheap hardware that today is out of reach,
if they can figure out how to use open source models
but make them more efficient
because you've got all these skilled applied statisticians
who are no longer caught up in the bubble,
then I think we could see some useful things
after the bubble.
That's my argument for this is fibre in the ground
and not shitty monkey JPEGs.
Modelling the speech
Cory mentioned using an open source model, whisper, to model speech audio as text; curious, I
used faster-whisper to transcribe the above section of the exchange before reading, checking, and
abridging
it by hand:
Below is the python script used to model the text: written by mistral codestral. As with
Cory, no GPU or fan was required (whisper has
been optimised). The editorial was by me: reading the modelled text, checking the
references, tidying the spelling, and bridging over the interjections of Ed Zitron who, despite making a decent
foil, seemed hellbent on the dystopian endgame, and less interested in what a salvage operation might look like.
# main.py
from faster_whisper import (WhisperModel)
import argparse
import requests
def main():
model_size = "medium"
model = WhisperModel( model_size, device="cpu", compute_type="int8",)
parser = argparse.ArgumentParser(description="Process an input spoken audio file (arg 1) from http(s) url or filepath and transcribe to file (arg 2)")
parser.add_argument("input_file", help="Input file path")
parser.add_argument( "output_file", help="Output file path")
args = parser.parse_args()
audio_file = read_file(args.input_file)
print(f"transcribing {args.input_file} to {args.output_file}")
segments, info = model.transcribe(audio_file,beam_size=5)
with open( args.output_file, "w", encoding="utf-8") as f:
for segment in segments:
line = f"[{segment.start:.2f}s -> {segment.end:.2f}s] {segment.text}\n"
print(line.strip()) # Print to console
f.write(line) # Print to file
print(f"\nTranscription saved to '{args.output_file}'")
def read_file(file_path):
if file_path.startswith("http://") or file_path.startswith("https://"):
response = requests.get(file_path, stream=True)
response.raise_for_status()
return response.raw
else:
fp = open(file_path, "rb")
return fp
if __name__ == "__main__":
main()
§
The innocence project
The paper referenced by Cory, "Innocence Discovery Lab - Harnessing Large Language Models to Surface Data Buried
in Wrongful Conviction Case Documents" described a method using language models "to transform unstructured
documents from case documents into a structured, accessible format." This is a practice known as Information
Extraction (IE).
The paper starts out by demonstrating the limitations of regex in extracting information due to its rules based
approach; high on accuracy, low on recall, with an inability to understand relational connections between
entities in text. In the first of a series of code extracts, an example regex used to find passages containing
named investigators is listed:
The paper goes on to identify a method for using LLMs to forge contextual similarity and semantic connections
between documents in a database using a multi-stage method, illustrated with code fragments repeated beneath:
Hypothetical Document Embeddings (HyDE)
Transform raw text into a structured, searchable format […]
searches leveraging these embeddings focus on contextual
similarity and semantic connections between documents,
surpassing traditional keyword-based search methods in depth and
relevance.
# Listing 2.0: Hypothetical Document Embeddings Query
PROMPT_TEMPLATE_HYDE = PromptTemplate(
input_variables=["question"], template="""You're an AI assistant
specializing in criminal justice research.Your main focus is on
identifying the names and providing detailed context of mention for each
law enforcement personnel. This includes police officers, detectives,
deputies, lieutenants, sergeants, captains, technicians, coroners,
investigators, patrolmen, and criminalists, as described in court
transcripts and police reports. Question: {question} Responses:"""
)
For segmentation, we use LangChain's
RecursiveCharacterTextSplitter, which divides the document
into word chunks. The chunk size and overlap are chosen to
ensure that each segment is comprehensive enough to maintain
context while being sufficiently small for efficient
processing. Post-segmentation, these chunks are transformed
into high-dimensional vectors using the hypothetical
document's embedding scheme.
The concluding step involves
the FAISS.from_documents function, which
compiles these vectors into an indexed database. This
database enables efficient and context- sensitive searches,
allowing for the quick identification of documents that
share content similarities with the hypothetical document.
# Listing 3: Storing the Document in a Vector Database
def process_single_document(file_path, embeddings):
logger.info(f"Processing document: {file_path}"
loader = JSONLoader(file_path)
text = loader.load()
logger.info(f"Text loaded from document: {file_path}")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,
chunk_overlap=250)
docs = text_splitter.split_documents(text)
db = FAISS.from_documents(docs, embeddings)
return db
Creating a prompt output format
The model then extracts information relevant to the query and
structures the output according to the specifications in the prompt template.
# Listing 4.0: Template for Model
PROMPT_TEMPLATE_MODEL = PromptTemplate(input_variables=["question",
"docs"],template=""
As an AI assistant, my role is to meticulously analyze criminal justice documents and
extract information about law enforcement personnel.
Query: {question}
Documents: {docs}
The response will contain:
1) The name of a police officer.
Please prefix the name with "Officer Name: ".
For example, "Officer Name: John Smith".
2) If available, provide an in-depth description of the context of their mention.
If the context induces ambiguity regarding the individuals role in law enforcement,
note this.
Please prefix this information with "Officer Context: ".
3) Review the context to discern the role of the officer. For example, Lead Detective.
Please prefix this information with "Officer Role: "
For example, "Officer Role: Lead Detective"
The full response should follow the format below, with no prefixes such as 1., 2., 3., a.,
b., c.:
Officer Name: John Smith
Officer Context: Mentioned as officer at the scene of the incident.
Officer Role: Patrol Officer
Officer Name:
Officer Context:
Officer Role:
Additional guidelines:
Only derive responses from factual information found within the police reports.
""",)
Initial Query Processing
The extraction phase begins when a
user sends a query to the vector database. Once the query is received,
the database conducts a search within its embedding space, identifying
and retrieving text chunks that best match the query's contextual and
semantic criteria. This retrieval process is carried out using the
db.similarity_search_with_score method, which selects the
top 'k' relevant chunks based on their high similarity to the
query.
Sorting of Retrieved Chunks
After their retrieval, the
chunks are sorted [to ensure relevant chunks are] appropriately
organized within the model’s context window […] After sorting,
the chunks are concatenated into a single string […] reducing
unnecessary tokens.
# Listing 4.1: Function for Generating Responses
def get_response_from_query(db, query):
# Set up the parameters
prompt = PROMPT_TEMPLATE_MODEL
roles = ROLE_TEMPLATE
temperature = 1
k = 20
# Perform the similarity search
doc_list = db.similarity_search_with_score(query, k=k)
# Sort documents by relevance scores as suggested in https://arxiv.org/abs/2307.03172
docs = sorted(doc_list, key=lambda x: x[1], reverse=True)
third = len(docs) // 3
highest_third = docs[:third]
middle_third = docs[third:2*third]
lowest_third = docs[2*third:]
highest_third = sorted(highest_third, key=lambda x: x[1],reverse=True)
middle_third = sorted(middle_third, key=lambda x: x[1], reverse=True)
lowest_third = sorted(lowest_third, key=lambda x: x[1], reverse=True)
sorted_docs = highest_third + lowest_third + middle_third
# Join documents into one string for processing
docs_page_content = " ".join([d[0].page_content for d in sortedocs])
Model Initialisation and Response Generation
The processing begins with the instantiation of an OpenAI model and
the LLMChain class. This setup allows the chain to process the combined
document content along with the original query. Following this, the
LLMChain executes its run method, using the inputs of prompt, query, and
document content to generate a structured and detailed response. The
model then extracts information relevant to the query and structures the
output according to the specifications in the prompt template.
# Create an instance of the OpenAI model
llm = ChatOpenAI(model_name="gpt-4")
# Create an instance of the LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the LLMChain and print the response
response = chain.run(question=query, docs=docs_page_content,
temperature=temperature)
print(response)
return response
The researchers additionally fine-tuned the model to use a cheaper
model, and outline a method to de-depulicate different mentions of the
same case workers in the database. Ultimately, they end up with a model
that can process investigations and extract a table with the following columns:
investigator name (de-duplicated)
investigator role (de-duplicated)
investigator involvement in a case (compiled)
Overall then, it looks like they are trying to find links between
wrongful conviction cases by looking for patterns of investigator
involvement across a collection of exoneration documents, possibly
helping uncover links to further potential exonerations.
2025-11-08
The long-tail of ideas coming from the geoplace conference in May continues!
This time I finally got round to open-sourcing and packaging up a python module
that links datasets by household:
It's a trio of functions which interact with the ASSIGN HTTP API:
validating single or multiple freetext addresses into their
definitive one-line form plus unique reference.
As well as validating addresses, the package also provides the ability to de-identify
property references into RALFs (Residential Anonymised Linkage Fields). Supporting
this feature does distract a bit from the simplicity of frictionless address matching.
Still... being able to de-identify property references is helpful in some applications,
such as research, testing, and data linking within the protection of the
Five Safes.
The slides i've been doing the rounds with are shown here. They are packed with links
to the source, docs, and package, plus various background materials on the
value of property references. It's worth remembering that in Britain, we seem to have
an aversion to national id, following prior abuses in the wake of wartime
rationing schemes, so cross-linking services by household is still the cleanest
way public servants have of tending to the information garden.
2025-09-14
At some point around 2023 TfL changed it's countdown API causing the household a
certain amount of inconvenience. We'd been heavy users of a long forgotten
app that went like the clappers (unlike the buses, thankfully) and offered a no-frills
highly usable experience when getting around town on four wheels.
It was called when-ze-bus
and no app before or since has given such clear assistance when trying to
tame the streets of London.
Having briefly considered rebooting the android toolchain (it's very very very long),
I simply decided to go again in web standards, so here we are ;
I hope you find it useful.
You can try out a bus stop on
Tottingham Court Road with shortCode 55563:
2025-07-22
There are no frogs in this porridge, but chia seeds give it a froggy consistency.
Quantities of ingredients are per person - when i say "two hands" this is based on a
cook once telling me that a stomach is about the size of two hands.
Cook for around three minutes, stirring occasionally with a fork to stop the
chia seeds sticking to each other.
2025-07-20
reaquainting myself with strudel ahead of AlgoRhythms and it's been fun. it started out on nudel.cc from where i borrowed a synth on friday evening, and then added some drums, percussion, and bass in strudel for a more compositional approach.
the style is influenced by some of the split tempo (170/85) music coming from Berlin, especially the Samurai podcasts by Donato Dozzy and Reeko.
take it easy with the room reverb function, it uses a lot of energy.
2025-07-14
Curious about local politics around the world? Press a location on the map to query wikidata! NOTE: This
doesn't always return results, and when it does they can be slow to arrive, plus their
temporal/spatial accuracy can be out of date/place due to old data or spatial oddities, since the match
is inferred by proximity to a local admin headquarters, which could be in a another area entirely,
yet still closer than the actual one…
Still, do give it a spin, wikidata is amazing after all.
TIP: Zoom to a locality first.
Making this map was fun; it started on a journey from Suffolk to London. On the way I visited Flatford Mill and
became curious about what the local politics were like. This soon turned into curiosity about what the local
politics are like anywhere. Amazingly, if not always consistently, wikidata covers this! With some
much needed sparql chops from le chat, I eventually settled on a query that addresses this
curiosity by tracking the party of the head of local government in the proximity of a geolocation:
SELECT DISTINCT ?location ?adminArea ?adminAreaLabel ?headPartyMembership ?headPartyMembershipLabel ?officialWebsite ?governingPartyWebsite
WHERE {
SERVICE wikibase:around {
?adminArea wdt:P625 ?location .
bd:serviceParam wikibase:center "Point(${longitude} ${latitude})"^^geo:wktLiteral .
bd:serviceParam wikibase:radius "8" .
bd:serviceParam wikibase:distance ?distance .
}
# Get administrative type
?adminArea wdt:P31 ?adminType .
# Must be an administrative entity
?area wdt:P31/wdt:P279* ?type .
?type wdt:P279* wd:Q34876 .
# Get the head of government and their party (if available)
{
# Get the head of government (P6)
?adminArea wdt:P6 ?governingParty .
# Get the party membership of the head of government (if available)
{
?governingParty wdt:P102 ?headPartyMembership .
}
}
# Get the official website (P856)
OPTIONAL {
?adminArea wdt:P856 ?officialWebsite .
}
# Get the official website of the governing party (P856)
OPTIONAL {
?governingParty wdt:P856 ?governingPartyWebsite .
}
SERVICE wikibase:label { bd:serviceParam wikibase:language "en" }
}
ORDER BY ?distance
LIMIT 1
Making this map was also fiddly; Sourcehut pages have a disciplined and excellent content security policy which means that:
All scripts and styles must be loaded from your own site, not a CDN
Fine by me, but when using maplibre this policy also applies to map tiles,
fonts, sprites etc. Initially I'd hoped this might provide a perfect reason to use protomaps (I was fortunate enough to meet the creator, bdon, at geomob and his approach
is great). Limiting zoom to level 6, which is close enough for cities, means you can tile the world in just 42MB!
Unfortunately this policy also precludes queries to wikidata, so in the end
I used an iframe to codeberg and
standard tiles from maptiler's content distribution network. Nonetheless tinkering with protomaps is nice, and
I'll look forward to making some data enriched tiles when the opportunity arises.
2025-05-29
geoplace conference was great. the keynote included this pearl of wisdom:
It is hard to compare addresses
It is easy to compare UPRNs
A UPRN (unique property reference number) is a permanent 12-digit standard location identifier for addressable places in Britain. This
machine-readable identifier can be linked ad hoc (with help from human-readable lookups) or post-hoc (matching algorithms). UPRN is a human-computer data bridge for places.
For example, consider tax and voting datasets. Using a left join to identify households that are contributing financially to democracy but not electorally, it becomes simple to post those households an invitation to the vote! Now imagine trying to join those datasets on addresses recorded in different systems in different ways?!
SELECT * FROM Taxpayers
LEFT JOIN Voters
ON Taxpayers.UPRN = Voters.UPRN
WHERE Voters.UPRN IS NULL
Inspiration strikes
Like all good conferences, geoplace brings ideas together and sometimes they collide leading new ideas to be forged; some good, some bad, and some (as in this case) just playful.
The overriding theme of the event is driving adoption of location standards across public services with the objective of enabling integration. Public service records contain place data very often since:
Everything that happens, happens somewhere
Standardising that "somewhere" helps services help each other, since locations are frequently the best bridge between them. Definitive shared place identifiers become the crown jewels of public service integration.
The conference had a workshop session where delegates had quickfire topical discussions, each with its own brief. My favourite: "Best kept secret" considered how to popularise standards, and went down an interesting accessibility route. This discussion brought a couple of fun ideas to mind:
Branding
Since the British Standards kitemark looks a bit like a loveheart; use it to invoke a call to action:
Love locations?
Love location standards! <💗>
…well… trademarks being what they are, this campaign is a complete non-starter; so let's proceed to the next idea:
Mnemonic Encoding/Decoding
Someone mentioned using what3words to rendezvous in a crowded place and I thought of w3w for UPRN. Yes w3w has found similar looking/sounding encodings for different places. Furthermore, applying word encoding to UPRN numbers is pointless since, like phone numbers, they are easily looked up in the definitive list; just as we don't need to remember phone numbers. Addresses already have a human form, so it's more about checking in with the definitive record than superimposing another layer of translation.
Still… i went ahead and did it anyway as it was fun playing with dictionary encoding - after trying through some linguistics corpora and wondering what to do about negative words, I asked Mistral to generate a neutral and familiar 1000-word list, it said:
Creating a list of 1000 words manually would be quite extensive […] Let's generate this list using some Python code. We'll start with a basic list and expand it to meet your requirements.
It then ran some python to pad a 732 long wordlist to 1000 with prefixes and suffixes.
prefixes = ["Super", "Hyper", "Mega",
"Ultra", "Mini", "Micro",
"Macro", "Multi"]
suffixes = ["-like", "-ish", "-esque",
"-ful", "-less", "-ness",
"-able", "-er"]
This is an optimising trick, and we know from w3w that plurals and similar looking/sounding words introduce ambiguities between locations. The honing of this dictionary will involve finding and replacing ambiguities - and testing for ambiguities is going to be a sidequest involving encoding a all the UPRNs and comparing them for similarity using some computational linguistics.
So far there's been an attempt to compute levenshtein distance between all the possible combinations using the rapidfuzz package, but quintillions of comparisons is computationally expensive, though it could be optimised and reduced by sorting in various ways and only comparing neighbours (
). I wonder how the person who found ambuiguity in w3w did their cross-comparisons?
Meanwhile… A 1000-word dictionary is enough to encode every possible combination of three digits so a 12 digit UPRN, such as the one for 10 Downing St, can be dictionary encoded into four words:
---
title: "Encoding the UPRN for 10 Downing St against a 1000 word dictionary"
config:
packet:
showBits: false
bitsPerRow: 40
rowHeight: 75
---
packet-beta
0-39: "10 Downing Street, London, SW1A 2AA"
40-79: "100023336956"
80-89: "100"
90-99: "023"
100-109: "336"
110-119: "956"
120-129: "Cucumber"
130-139: "Lasagne"
140-149: "Submarine"
150-159: "SuperCarpet"
160-199: "1000 word dictionary"
if i wanted three words instead of four, the dictionary would have to be four-to-the-power-of-ten words long i.e. 10,000 - and even getting to 1,000 introduced potential for ambiguity.
Mistral vibe-coded the below tool to encode/decode uprns to/from word quads in addition to providing a 1000-strong dictionary. I preferred this list to a few I had found on the web such as most common British words, as these sometimes included negative sounding words like fear and loathing, although real places have difficult names too, like "Cape Wrath Lighthouse". Mistral seemed to stay neutral in its word selection.
The tool is shared below, as is my rambling conversation with Le Chat - Here's a few UPRNs to consider: